Bluesky Sentiment Indexing
Starter Pack Cohorts
By Steve Ewing in Bluesky
November 22, 2024
First get the starter packs for a given vector of actors, then get the people in each starter pack.
library(tidyverse)
library(httr2)
actor_identifiers <- c("marcelias.bsky.social", #politics
"flavorflav.bsky.social", #entertainment
"hltco.bsky.social", #sports
"katharinehayhoe.com") #science
get_people_in_starter_packs <- function(actor_identifiers) {
# Create a logged-in API session object once
session <- request("https://bsky.social/xrpc/com.atproto.server.createSession") |>
req_method("POST") |>
req_body_json(list(
identifier = Sys.getenv("BLUESKY_APP_USER"),
password = Sys.getenv("BLUESKY_APP_PASS")
)) |>
req_perform() |>
resp_body_json()
# Initialize an empty tibble to hold all items from all actors
all_actors_items_df <- tibble()
# Loop over each actor_identifier
for (actor_identifier in actor_identifiers) {
# Fetch starter packs for the current actor_identifier
req <- request("https://bsky.social/xrpc/app.bsky.graph.getActorStarterPacks") |>
req_method("GET") |>
req_headers(Authorization = paste0("Bearer ", session$accessJwt)) |>
req_url_query(actor = actor_identifier)
resp <- req |> req_perform()
starter_packs <- resp_body_json(resp)
starter_packs_list <- starter_packs$starterPacks
# Check if starter_packs_list is empty or NULL
if (is.null(starter_packs_list) || length(starter_packs_list) == 0) {
message("No starter packs found for actor: ", actor_identifier)
next # Skip to next actor_identifier
}
# Unnest the nested list into a tibble
unnested_sp <- map_dfr(
starter_packs_list,
~ tibble(
uri = .x$uri,
cid = .x$cid,
record_type = .x$record$`$type`,
record_createdAt = .x$record$createdAt,
record_description = .x$record$description,
record_list = .x$record$list,
record_name = .x$record$name,
record_updatedAt = .x$record$updatedAt,
creator_did = .x$creator$did,
creator_handle = .x$creator$handle,
creator_displayName = .x$creator$displayName,
creator_avatar = .x$creator$avatar,
creator_viewer_muted = .x$creator$viewer$muted,
creator_viewer_blockedBy = .x$creator$viewer$blockedBy,
creator_viewer_following = .x$creator$viewer$following,
creator_createdAt = .x$creator$createdAt,
joinedAllTimeCount = .x$joinedAllTimeCount,
joinedWeekCount = .x$joinedWeekCount,
indexedAt = .x$indexedAt,
actor_identifier = actor_identifier # Add actor_identifier to the tibble
)
)
# Initialize an empty tibble to hold all items from all lists of this actor
all_items_df <- tibble()
# Loop over each record in unnested_sp
for (i in seq_len(nrow(unnested_sp))) {
# Extract list URI, name, and creator handle for the current starter pack
list_uri <- unnested_sp$record_list[i]
record_name <- unnested_sp$record_name[i]
creator_handle <- unnested_sp$creator_handle[i]
# Initialize an empty list to hold items from this list
all_items <- list()
# Initialize cursor as NULL
cursor <- NULL
repeat {
# Construct the GET request
req <- request("https://bsky.social/xrpc/app.bsky.graph.getList") |>
req_method("GET") |>
req_headers(Authorization = paste0("Bearer ", session$accessJwt)) |>
req_url_query(list = list_uri)
# If cursor is not NULL, add it to the query
if (!is.null(cursor)) {
req <- req |> req_url_query(cursor = cursor)
}
# Perform the request
resp <- req |>
req_error(
is_error = function(resp)
FALSE
) |>
req_perform()
# Check if the response is an error
if (resp_status(resp) >= 400) {
message("An error occurred: ", resp_status_desc(resp))
# Optionally, print the response body for more details
print(resp_body_string(resp))
break
}
# Parse the response
list_data <- resp_body_json(resp)
# Extract items and append to all_items
all_items <- c(all_items, list_data$items)
# Update cursor
if (!is.null(list_data$cursor)) {
cursor <- list_data$cursor
} else {
# No more pages to fetch
break
}
}
# Now process all_items, adding record_name and creator_handle
items_df <- map_dfr(all_items, function(item) {
tibble(
uri = item$uri,
did = item$subject$did %||% NA_character_,
handle = item$subject$handle %||% NA_character_,
displayName = item$subject$displayName %||% NA_character_,
avatar = item$subject$avatar %||% NA_character_,
description = item$subject$description %||% NA_character_,
createdAt = item$subject$createdAt %||% NA_character_,
indexedAt = item$subject$indexedAt %||% NA_character_,
record_name = record_name, # Add the record_name here
creator_handle = creator_handle # Add the creator_handle here
)
})
# Append items_df to all_items_df for this actor
all_items_df <- bind_rows(all_items_df, items_df)
}
# Append all_items_df for this actor to the overall all_actors_items_df
all_actors_items_df <- bind_rows(all_actors_items_df, all_items_df)
}
# Return the combined data frame
all_actors_items_df
}
people_in_starter_packs <- get_people_in_starter_packs(actor_identifiers)
Now get all the posts up until now for all the people in the starter packs.
# # Function to get posts from a vector of handles
# get_posts_from_handles <- function(handles) {
#
# # Create a logged-in API session object once
# session <- request("https://bsky.social/xrpc/com.atproto.server.createSession") |>
# req_method("POST") |>
# req_body_json(list(
# identifier = Sys.getenv("BLUESKY_APP_USER"),
# password = Sys.getenv("BLUESKY_APP_PASS")
# )) |>
# req_perform() |>
# resp_body_json()
#
# # Initialize an empty tibble to hold all posts
# all_posts_df <- tibble()
#
# # Loop over each handle
# for (handle in handles) {
# message("Fetching posts for handle: ", handle)
#
# # Initialize an empty list to hold posts for this handle
# all_posts <- list()
#
# # Initialize cursor as NULL
# cursor <- NULL
#
# repeat {
# # Construct the GET request
# req <- request("https://bsky.social/xrpc/app.bsky.feed.getAuthorFeed") |>
# req_method("GET") |>
# req_headers(Authorization = paste0("Bearer ", session$accessJwt)) |>
# req_url_query(actor = handle)
#
# # If cursor is not NULL, add it to the query
# if (!is.null(cursor)) {
# req <- req |> req_url_query(cursor = cursor)
# }
#
# # Perform the request
# resp <- req |>
# req_error(is_error = function(resp) FALSE) |>
# req_perform()
#
# # Check if the response is an error
# if (resp_status(resp) >= 400) {
# message("An error occurred fetching posts for ", handle, ": ", resp_status_desc(resp))
# # Optionally, print the response body for more details
# print(resp_body_string(resp))
# break
# }
#
# # Parse the response
# feed_data <- resp_body_json(resp)
#
# # Check if feed is empty
# if (length(feed_data$feed) == 0) {
# message("No posts found for handle: ", handle)
# break
# }
#
# # Extract posts and append to all_posts
# all_posts <- c(all_posts, feed_data$feed)
#
# # Update cursor
# if (!is.null(feed_data$cursor)) {
# cursor <- feed_data$cursor
# } else {
# # No more pages to fetch
# break
# }
#
# # Optional: Pause to respect rate limits
# Sys.sleep(0.1)
# }
#
# # Now process all_posts into a tibble
# posts_df <- map_dfr(all_posts, function(post) {
# tibble(
# uri = post$post$uri,
# cid = post$post$cid,
# author_did = post$post$author$did %||% NA_character_,
# author_handle = post$post$author$handle %||% NA_character_,
# author_displayName = post$post$author$displayName %||% NA_character_,
# record_type = post$post$record$`$type` %||% NA_character_,
# record_text = post$post$record$text %||% NA_character_,
# record_createdAt = post$post$record$createdAt %||% NA_character_,
# reply_root = post$post$record$reply$root$uri %||% NA_character_,
# reply_parent = post$post$record$reply$parent$uri %||% NA_character_,
# repost_count = post$post$repostCount %||% NA_integer_,
# reply_count = post$post$replyCount %||% NA_integer_,
# like_count = post$post$likeCount %||% NA_integer_,
# indexed_at = post$post$indexedAt %||% NA_character_
# )
# })
#
# # Append posts_df to all_posts_df
# all_posts_df <- bind_rows(all_posts_df, posts_df)
# }
#
# # Return the combined posts data frame
# all_posts_df
# }
#
# # Fetch posts for all handles
# all_posts_df <- get_posts_from_handles(unique(all_items_df$handle))
# # View the resulting posts dataset
# print(all_posts_df)
Load the saved data from the database.
library(duckdb)
## Loading required package: DBI
library(DBI)
# Create or connect to a DuckDB database file
con <- dbConnect(duckdb::duckdb(), "bluesky_data.duckdb")
# Save the people_in_starter_packs data frame to the database
dbWriteTable(con, "people_in_starter_packs", people_in_starter_packs, overwrite = TRUE)
# # Save the all_posts_df data frame to the database
# dbWriteTable(con, "posts", all_posts_df, overwrite = TRUE)
Update the posts in the database.
# Function to update posts in the database
update_posts_in_database <- function() {
library(DBI)
library(duckdb)
library(httr2)
library(tidyverse)
library(parsedate) # Added to handle ISO 8601 timestamp parsing
# Create a logged-in API session object once
session <- request("https://bsky.social/xrpc/com.atproto.server.createSession") |>
req_method("POST") |>
req_body_json(list(
identifier = Sys.getenv("BLUESKY_APP_USER"),
password = Sys.getenv("BLUESKY_APP_PASS")
)) |>
req_perform() |>
resp_body_json()
# Connect to the database
con <- dbConnect(duckdb::duckdb(), "bluesky_data.duckdb")
# Get the list of handles from the people_in_starter_packs table
handles_df <- dbGetQuery(con, "SELECT DISTINCT handle FROM people_in_starter_packs")
handles <- handles_df$handle
# Initialize a tibble to hold new posts
new_posts_df <- tibble()
# Loop over each handle
for (handle in handles) {
message("Updating posts for handle: ", handle)
# Get the latest record_createdAt for this handle from the posts table
latest_time_query <- sprintf(
"SELECT MAX(record_createdAt) as latest_time FROM posts WHERE author_handle = '%s'",
handle
)
latest_time_result <- dbGetQuery(con, latest_time_query)
latest_time <- latest_time_result$latest_time[1]
# If there is no latest_time (i.e., no posts for this handle), set to NULL
if (is.na(latest_time) || is.null(latest_time)) {
latest_time <- NULL
message("No existing posts found for handle: ", handle)
} else {
message("Latest post time for ", handle, ": ", latest_time)
}
# Initialize variables for fetching posts
all_posts <- list()
cursor <- NULL
keep_fetching <- TRUE
repeat {
# Construct the GET request
req <- request("https://bsky.social/xrpc/app.bsky.feed.getAuthorFeed") |>
req_method("GET") |>
req_headers(Authorization = paste0("Bearer ", session$accessJwt)) |>
req_url_query(actor = handle)
# If cursor is not NULL, add it to the query
if (!is.null(cursor)) {
req <- req |> req_url_query(cursor = cursor)
}
# Perform the request
resp <- req |>
req_error(is_error = function(resp) FALSE) |>
req_perform()
# Check if the response is an error
if (resp_status(resp) >= 400) {
message("An error occurred fetching posts for ", handle, ": ", resp_status_desc(resp))
# Optionally, print the response body for more details
print(resp_body_string(resp))
break
}
# Parse the response
feed_data <- resp_body_json(resp)
# Check if feed is empty
if (length(feed_data$feed) == 0) {
message("No posts found for handle: ", handle)
break
}
# Process posts and check timestamps
posts_to_add <- list()
for (post in feed_data$feed) {
post_time <- post$post$record$createdAt %||% ""
if (post_time == "") next # Skip if no timestamp
# Parse the timestamps using parsedate::parse_iso_8601
post_time_parsed <- parse_iso_8601(post_time)
latest_time_parsed <- if (!is.null(latest_time)) parse_iso_8601(latest_time) else NULL
# Compare post_time with latest_time
if (!is.null(latest_time_parsed) && !is.na(post_time_parsed) && post_time_parsed <= latest_time_parsed) {
# Reached posts we've already fetched
keep_fetching <- FALSE
break
} else {
# New post, add to the list
posts_to_add <- c(posts_to_add, list(post))
}
}
# Append new posts to all_posts
all_posts <- c(all_posts, posts_to_add)
# Break the loop if we've reached existing posts
if (!keep_fetching) {
break
}
# Update cursor
if (!is.null(feed_data$cursor)) {
cursor <- feed_data$cursor
} else {
# No more pages to fetch
break
}
# Optional: Pause to respect rate limits
Sys.sleep(0.1)
}
# If there are new posts, process and insert them into the database
if (length(all_posts) > 0) {
message("Found ", length(all_posts), " new posts for handle: ", handle)
# Process the new posts into a tibble
posts_df <- map_dfr(all_posts, function(post) {
tibble(
uri = post$post$uri,
cid = post$post$cid,
author_did = post$post$author$did %||% NA_character_,
author_handle = post$post$author$handle %||% NA_character_,
author_displayName = post$post$author$displayName %||% NA_character_,
record_type = post$post$record$`$type` %||% NA_character_,
record_text = post$post$record$text %||% NA_character_,
record_createdAt = post$post$record$createdAt %||% NA_character_,
reply_root = post$post$record$reply$root$uri %||% NA_character_,
reply_parent = post$post$record$reply$parent$uri %||% NA_character_,
repost_count = post$post$repostCount %||% NA_integer_,
reply_count = post$post$replyCount %||% NA_integer_,
like_count = post$post$likeCount %||% NA_integer_,
indexed_at = post$post$indexedAt %||% NA_character_
)
})
# Write the new posts to the database
dbWriteTable(con, "posts", posts_df, append = TRUE)
} else {
message("No new posts found for handle: ", handle)
}
}
# Disconnect from the database
dbDisconnect(con, shutdown = TRUE)
}
update_posts_in_database()
Add sentiment scoring
compute_sentiment_scores <- function() {
library(DBI)
library(duckdb)
library(tidyverse)
library(tidytext)
# Connect to the database
con <- dbConnect(duckdb::duckdb(), "bluesky_data.duckdb")
# Read the posts table
posts_df <- dbReadTable(con, "posts")
# Ensure record_text is not NA
posts_df <- posts_df %>% filter(!is.na(record_text))
# Select relevant columns
posts_df <- posts_df %>% select(uri, record_text)
# Tokenize the text
posts_tokens <- posts_df %>%
unnest_tokens(word, record_text)
# Get the AFINN sentiment lexicon
afinn <- get_sentiments("afinn")
# Join tokens with sentiment lexicon
posts_sentiment <- posts_tokens %>%
inner_join(afinn, by = "word")
# Compute sentiment score per post
post_sentiment_scores <- posts_sentiment %>%
group_by(uri) %>%
summarise(sentiment_score = sum(value))
# Handle posts without sentiment words
all_uris <- posts_df$uri
post_sentiment_scores <- tibble(uri = all_uris) %>%
left_join(post_sentiment_scores, by = "uri") %>%
mutate(sentiment_score = replace_na(sentiment_score, 0))
# Write the sentiment scores to the database
dbWriteTable(con, "post_sentiment_scores", post_sentiment_scores, overwrite = TRUE)
# Disconnect from the database
dbDisconnect(con, shutdown = TRUE)
}
compute_sentiment_scores()
# Reconnect to the database
con <- dbConnect(duckdb::duckdb(), "bluesky_data.duckdb")
# Join posts with sentiment scores
posts_with_sentiment <- dbGetQuery(con, "
SELECT p.*, s.sentiment_score
FROM posts p
LEFT JOIN post_sentiment_scores s ON p.uri = s.uri
")
# Disconnect from the database
dbDisconnect(con, shutdown = TRUE)
# View the data frame
head(posts_with_sentiment)
## uri
## 1 at://did:plc:mkyjjkt5uwobjstft6x4tfy4/app.bsky.feed.post/3k4mkgq7qrq2l
## 2 at://did:plc:s3usd6r2ja3vjwazopbk3iaz/app.bsky.feed.post/3k32voqufko2r
## 3 at://did:plc:uynpich2hsqmryyhr3moz5re/app.bsky.feed.post/3k4kpjh6btq2b
## 4 at://did:plc:nf66nltcbiomd5u3fpj4b42v/app.bsky.feed.post/3k4kn4qsg6c22
## 5 at://did:plc:mkyjjkt5uwobjstft6x4tfy4/app.bsky.feed.post/3k4kw7ekd6e2w
## 6 at://did:plc:mkyjjkt5uwobjstft6x4tfy4/app.bsky.feed.post/3k4kvs75bps2l
## cid
## 1 bafyreicqps4jg7m7hwhxu32xcy4atzydfj422d6hqki6g4kthbiqxnbw2e
## 2 bafyreihfqxay3elo4nav2udxgnz3ir2zdxqy4mra7ixbfpcp6sgmun2isy
## 3 bafyreiew3apfmapto5qcwx5dkb7eabanadtntb3li2salirhu2wvuc7p2u
## 4 bafyreih4qjymynxmkraidjis7brvz4rnzsizubrlurpraxliney33b2sj4
## 5 bafyreidk3437fs4lluj26kfn6fba3wn2abwhwozrqpucnywmstydfc6r2u
## 6 bafyreiaqzji2vyc4sbmuluqafrnvip4rwad7epfxxyzfwdjzjvhef3go4u
## author_did author_handle
## 1 did:plc:mkyjjkt5uwobjstft6x4tfy4 tessafisher.bsky.social
## 2 did:plc:s3usd6r2ja3vjwazopbk3iaz lucriesbeck.bsky.social
## 3 did:plc:uynpich2hsqmryyhr3moz5re pavedwalden.bsky.social
## 4 did:plc:nf66nltcbiomd5u3fpj4b42v punkrockscience.bsky.social
## 5 did:plc:mkyjjkt5uwobjstft6x4tfy4 tessafisher.bsky.social
## 6 did:plc:mkyjjkt5uwobjstft6x4tfy4 tessafisher.bsky.social
## author_displayName record_type
## 1 Dr. Tessa Fisher app.bsky.feed.post
## 2 luc is figuring it out ♻️🛰️ app.bsky.feed.post
## 3 pavedwalden app.bsky.feed.post
## 4 Dr. Stephanie app.bsky.feed.post
## 5 Dr. Tessa Fisher app.bsky.feed.post
## 6 Dr. Tessa Fisher app.bsky.feed.post
## record_text
## 1 The frequency of paranoid reading on this site as of late is getting pretty exhausting
## 2 Hi.\n\nI’m trying to raise funds for my top surgery.\n\nAs of this morning, about 37% of my goal has been met.\n\nI’m beyond grateful for your support, and I still need your help to get me closer to this procedure.\n\nCan you help me spread the word?\n\nThank you! \n\nhttps://gofund.me/f39217a4
## 3 When you see someone getting main charactered, I want you to notice how people feed off each other's anger, "yes and"ing each dunk, finding new angles of attack, building a narrative around the target. It feels good to be in agreement. It feels good to be funny. It feels better than being fair.
## 4 NIH postdocs want a union!\n\nBetter pay, better workplace protections, better healthcare… And because so many other postdocs peg salaries to the NIH scale, this could benefit far more people than just at the NIH.\n\nThe NIH tried (and has now recanted) “they’re not employees”.\n\nUNION STRONG, FRIENDS! 🧪
## 5 I, for one, look forward to the day when trans women will be free to post about other things in addition to discourse and shitposts
## 6 First off, this is an excellent choice of names for a star.\n\nSecondly, stellar astro folks, do we have an idea if Earendel is actually Pop III or not?
## record_createdAt
## 1 2023-08-10T16:29:23.978Z
## 2 2023-07-21T22:37:37.871Z
## 3 2023-08-09T22:55:04.949Z
## 4 2023-08-09T22:12:11.362Z
## 5 2023-08-10T00:54:42.746Z
## 6 2023-08-10T00:47:20.265Z
## reply_root
## 1 <NA>
## 2 <NA>
## 3 at://did:plc:uynpich2hsqmryyhr3moz5re/app.bsky.feed.post/3k4kphtkvvd2g
## 4 <NA>
## 5 <NA>
## 6 <NA>
## reply_parent
## 1 <NA>
## 2 <NA>
## 3 at://did:plc:uynpich2hsqmryyhr3moz5re/app.bsky.feed.post/3k4kphtkvvd2g
## 4 <NA>
## 5 <NA>
## 6 <NA>
## repost_count reply_count like_count indexed_at sentiment_score
## 1 0 0 0 2023-08-10T16:29:23.978Z 1
## 2 5 1 4 2023-07-21T22:37:37.871Z 13
## 3 52 4 162 2023-08-09T22:55:04.949Z 13
## 4 13 1 27 2023-08-09T22:12:11.362Z 10
## 5 1 0 10 2023-08-10T00:54:42.746Z 1
## 6 0 0 2 2023-08-10T00:47:20.265Z 3
Indexing
library(tidyverse)
library(lubridate)
# Reconnect to the database
con <- dbConnect(duckdb::duckdb(), "bluesky_data.duckdb")
# Load posts with sentiment scores
posts_with_sentiment <- dbGetQuery(con, "
SELECT p.*, s.sentiment_score
FROM posts p
LEFT JOIN post_sentiment_scores s ON p.uri = s.uri
")
# Load starter pack information
starter_packs_df <- dbReadTable(con, "people_in_starter_packs")
# Disconnect from the database
dbDisconnect(con, shutdown = TRUE)
# Merge posts with starter pack information
posts_with_starter_pack <- posts_with_sentiment %>%
left_join(starter_packs_df %>% select(handle, record_name, creator_handle), by = c("author_handle" = "handle")) %>%
# Ensure 'record_createdAt' is parsed as POSIXct
mutate(
record_createdAt = as.POSIXct(record_createdAt, format = "%Y-%m-%dT%H:%M:%OSZ", tz = "UTC"),
date = as.Date(record_createdAt),
sentiment_score = replace_na(sentiment_score, 0))
## Warning in left_join(., starter_packs_df %>% select(handle, record_name, : Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 81 of `x` matches multiple rows in `y`.
## ℹ Row 1503 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.
# Calculate the overall average sentiment score
overall_average_sentiment <- mean(posts_with_starter_pack$sentiment_score, na.rm = TRUE)
# Group by date and starter pack name to compute daily averages
daily_sentiment <- posts_with_starter_pack %>%
group_by(date, author_handle, creator_handle) %>%
summarise(avg_sentiment_handles = mean(sentiment_score, na.rm = TRUE),
.groups = "drop") %>%
group_by(date, creator_handle) %>%
summarise(
average_sentiment = mean(avg_sentiment_handles, na.rm = TRUE),
.groups = "drop"
) %>%
filter(date >= floor_date(Sys.Date(), "month"),
!is.na(creator_handle))
library(ggplot2)
library(scales)
##
## Attaching package: 'scales'
## The following object is masked from 'package:purrr':
##
## discard
## The following object is masked from 'package:readr':
##
## col_factor
library(viridis)
## Loading required package: viridisLite
##
## Attaching package: 'viridis'
## The following object is masked from 'package:scales':
##
## viridis_pal
# Plot the sentiment index over time with every other day on the x-axis
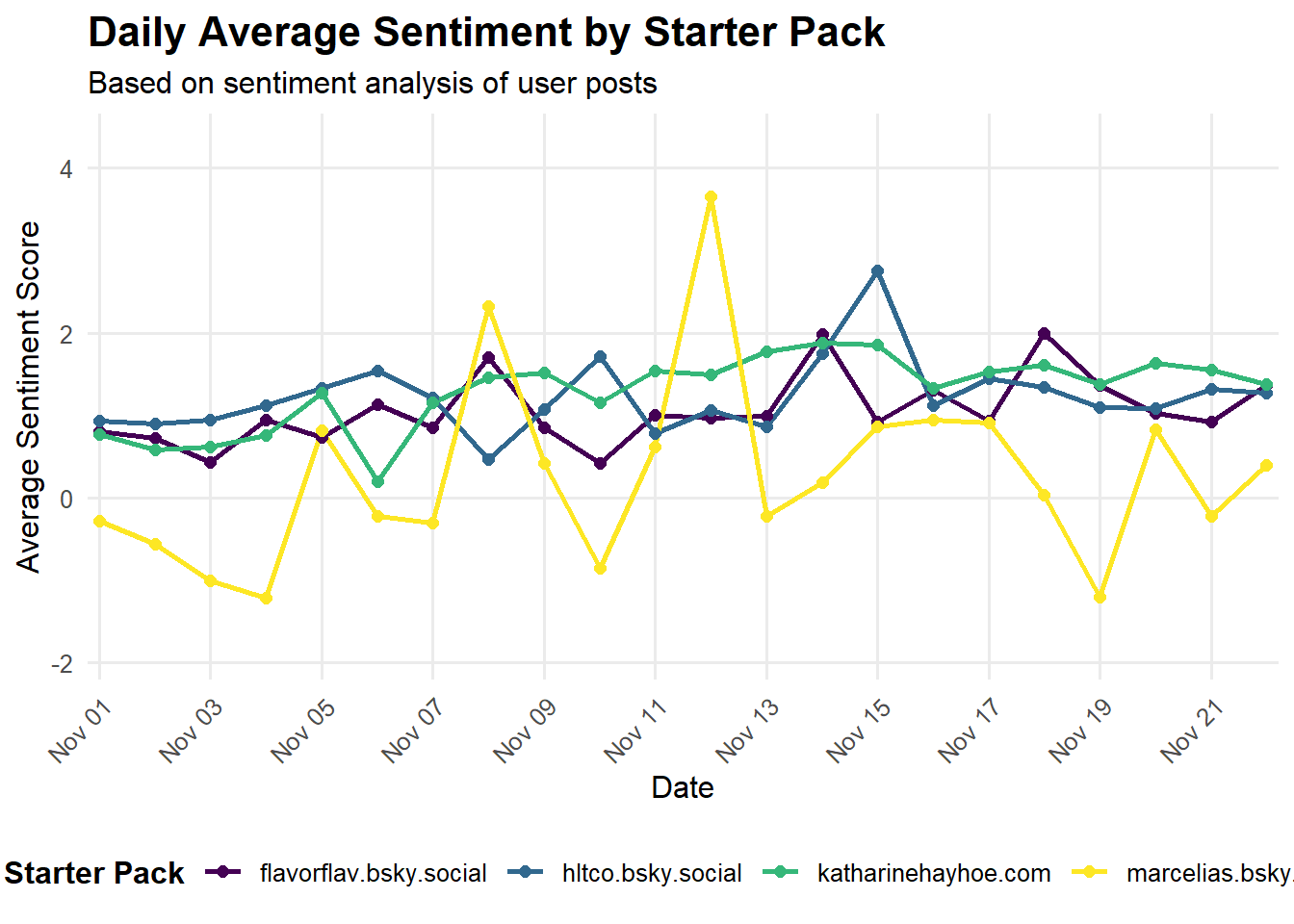
plot <- ggplot(daily_sentiment, aes(x = date, y = average_sentiment, color = creator_handle)) +
geom_line(size = 1) +
geom_point(size = 2) +
scale_color_viridis(discrete = TRUE, option = "D") +
scale_x_date(
date_labels = "%b %d",
date_breaks = "2 days",
expand = c(0.01, 0)
) +
scale_y_continuous(
limits = c(min(daily_sentiment$average_sentiment) - 1, max(daily_sentiment$average_sentiment) + 1),
expand = c(0, 0)
) +
labs(
title = "Daily Average Sentiment by Starter Pack",
subtitle = "Based on sentiment analysis of user posts",
x = "Date",
y = "Average Sentiment Score",
color = "Starter Pack"
) +
theme_minimal(base_size = 12) +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(face = "bold", size = 16),
plot.subtitle = element_text(size = 12),
legend.title = element_text(face = "bold"),
legend.position = "bottom",
panel.grid.minor = element_blank()
)
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.
ggsave("featured.jpg", plot, width = 6, height = 3, device = "jpg")
# Disconnect from the database
dbDisconnect(con, shutdown = TRUE)
## Warning: Connection already closed.
plot